Data Hallucinations in Generative AI Software Development Across Seven Models
Figure 1 shows that the earliest frontier models routinely produced upgrade suggestions that could not exist in the real world. Instead of selecting from published releases, they often generated version numbers that no registry would resolve, a failure mode that wastes tokens and increases build time.

At the rates observed in previous models (around one in four recommendations for models like Claude Sonnet 3.7, Gemini 2.5 Pro, and GPT-5), hallucinations are not an edge-case anomaly. It meant that version selection itself was unreliable without external validation. Now, the rate of hallucinations has decreased almost 4x.
This is real progress. But even the best ungrounded model still fabricates roughly 1 in 16 recommendations, a non-trivial error rate at machine scale. However, the way this improvement was achieved introduces a new problem.
AI Models Exercise Caution, But Recommend Inaction
Figure 2 explains how this happened. Models didn’t hallucinate nearly as much; instead, they simply got more cautious when uncertain.

Across providers, “no-change” recommendations, or cases where the model advises “stay on what you have,” nearly doubled over the same period that hallucination rates fell.

Why Does AI Recommend “No Change?”
The LLMs will provide a basis for their decision-making when asked. Below are a few scenarios and their associated reasoning for when the models recommended staying on the current version in this sample:
- Deprecated with a known successor: The component is end-of-life and has a named replacement (e.g., cx-Oracle → python-oracledb, Hystrix → Resilience4j). The model infers that upgrading within a deprecated package adds little value and defaults to the current version, though identifying deprecation from stale training data remains difficult.
- Mature and stable: The component has not had a newer version published in months or years. The model determines there is simply nothing to upgrade to (object-keys, Brotli, sniffio).
- Near the LLM's training data boundary: The component version is recent enough that the LLM is unable to confirm whether a newer patch exists. Therefore, it defaults to recommending the current version rather than guessing (jackson-annotations 2.19.0, Flask 3.1.1).
- Niche or obscure: The LLM doesn't have enough data about the component to make a confident recommendation, so it falls back to "stay on current" as the safest advice (IBM WebSphere SPI packages, image-ssim).
- Rapidly evolving: A component’s version releases outpace training data. Some components ship so frequently that the LLM knows its recommendation will be stale almost immediately, so it punts (e.g., mypy-boto3-*, openai, langsmith).
In other words, AI model hallucination and inaction are not opposites. They are two sides of the same coin. Both are symptoms of reasoning without the data required to determine the correct upgrade path. The real issue is the price we pay for their restraint. What happens to vulnerability exposure when a third of components receives a “stay put” recommendation?
The Cost of Inaction in AI Software Development
So, what does doing nothing actually preserve? Across models, there are some vulnerabilities that simply do not have a remediation path, and most same-version recommendations (approximately 93-95% across models) do land on clean components — that matters.
But breaking the retained vulnerabilities into individual severity tiers reveals the true shape of the risk. Critical and High CVEs are not statistical outliers buried beneath a large base of Low-severity findings. They are the primary drivers of retained exposure in same-version recommendations.
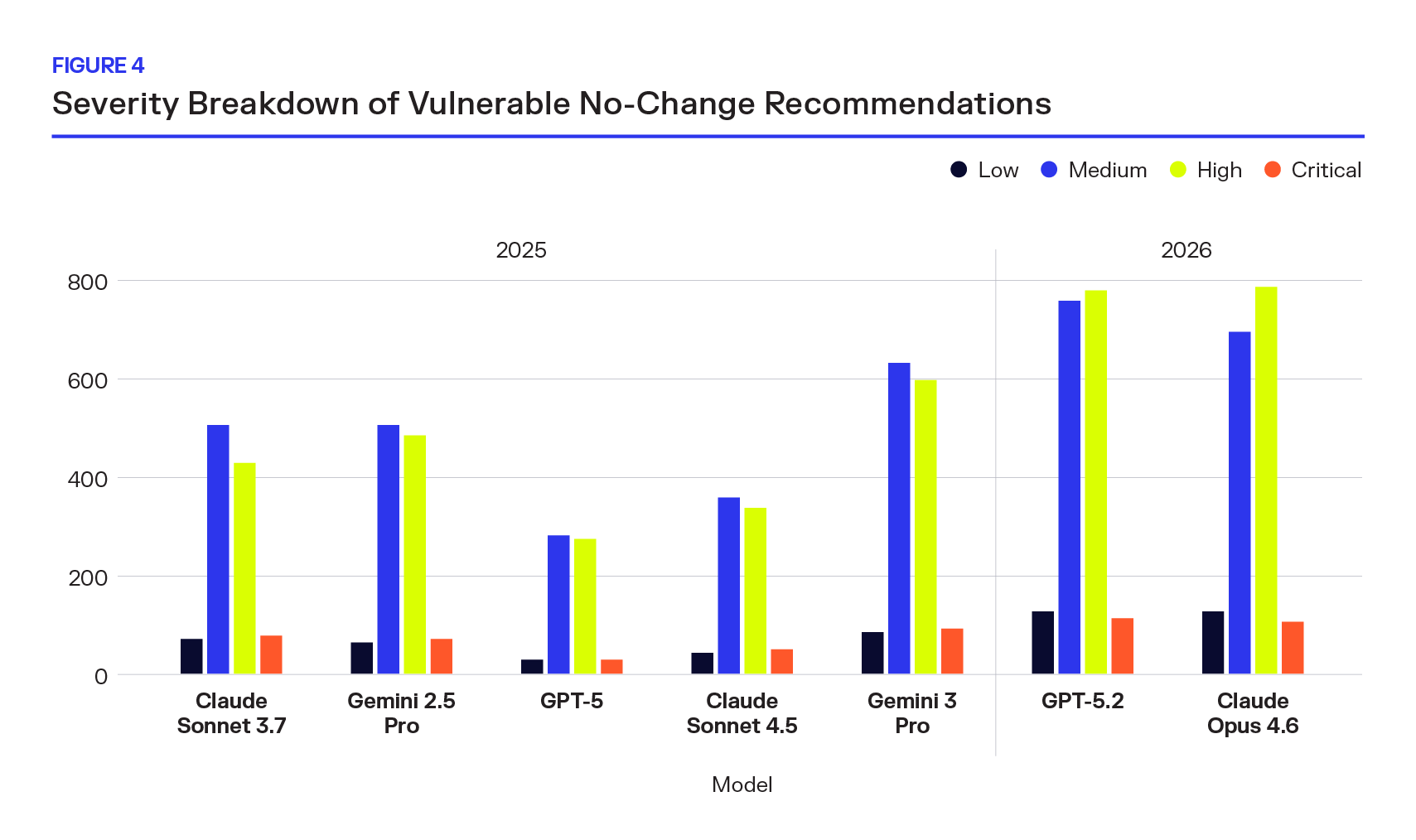
A Structural Pattern, Not a Vendor Artifact
Plotting each model’s “no-change” rate against its retained Critical and High vulnerability count makes the relationship unmistakable. As “no-change” rates increase, retained High-severity risk increases with them. And this is not isolated — the correlation is provider-agnostic.
OpenAI’s GPT-5.2, Anthropic’s Claude Opus 4.6, and Google’s Gemini 3 Pro all sit in the top-right quadrant of the chart, the region defined by the highest levels of caution and the highest levels of retained Critical and High exposure. Earlier models cluster toward the lower-left: lower “no-change” rates and lower retained High-severity counts, despite higher rates of hallucinated versions. The trajectory is consistent across vendors and model families.

This matters because it rules out a simple explanation like “one provider tuned too conservatively.” Instead, the pattern suggests something systemic about ungrounded LLMs operating in dependency management tasks. The result of caution is a predictable tradeoff.
Reducing AI model hallucination improves headline accuracy metrics, but retained vulnerability exposure rises in parallel. Without grounding in real-time supply chain intelligence, ungrounded LLMs appear to face a ceiling: they can guess and risk fabricating versions, or they can default and preserve existing exposure. Across providers, the models are choosing the latter.
The Grounding Gap: Real-Time Intelligence Eliminates Avoidable Risk
Figure 6 isolates what may be the most important distinction in this analysis: how much of the retained high-severity risk is actually unavoidable, and how much is simply the result of incomplete information.
The blue bars show the Critical and High vulnerabilities each model preserves by recommending “stay put.” The orange bars show what would remain if those same component recommendations were made with real-time intelligence applied and have No Path Forward.
The difference between the two is avoidable risk.

For the most cautious models, the numbers are stark. Across every provider and model generation, the Hybrid approach reduces retained high-severity exposure by more than half — often substantially more at 70-90%.

Where the Risk Concentrates: Ecosystem Differences
The top-line results in this study are directionally consistent across the full dataset, but software ecosystems are not interchangeable. Maven Central, npm, and PyPI differ in scale, release behavior, and versioning patterns, which makes it important to understand whether the same performance gaps hold when dependency recommendations are broken out by ecosystem.
The answer is yes: ecosystem differences change the shape of model failure, but not the conclusion. Figure 7 shows that Sonatype’s Hybrid approach delivers materially stronger security outcomes in every ecosystem with a meaningful sample size than any LLM alone.
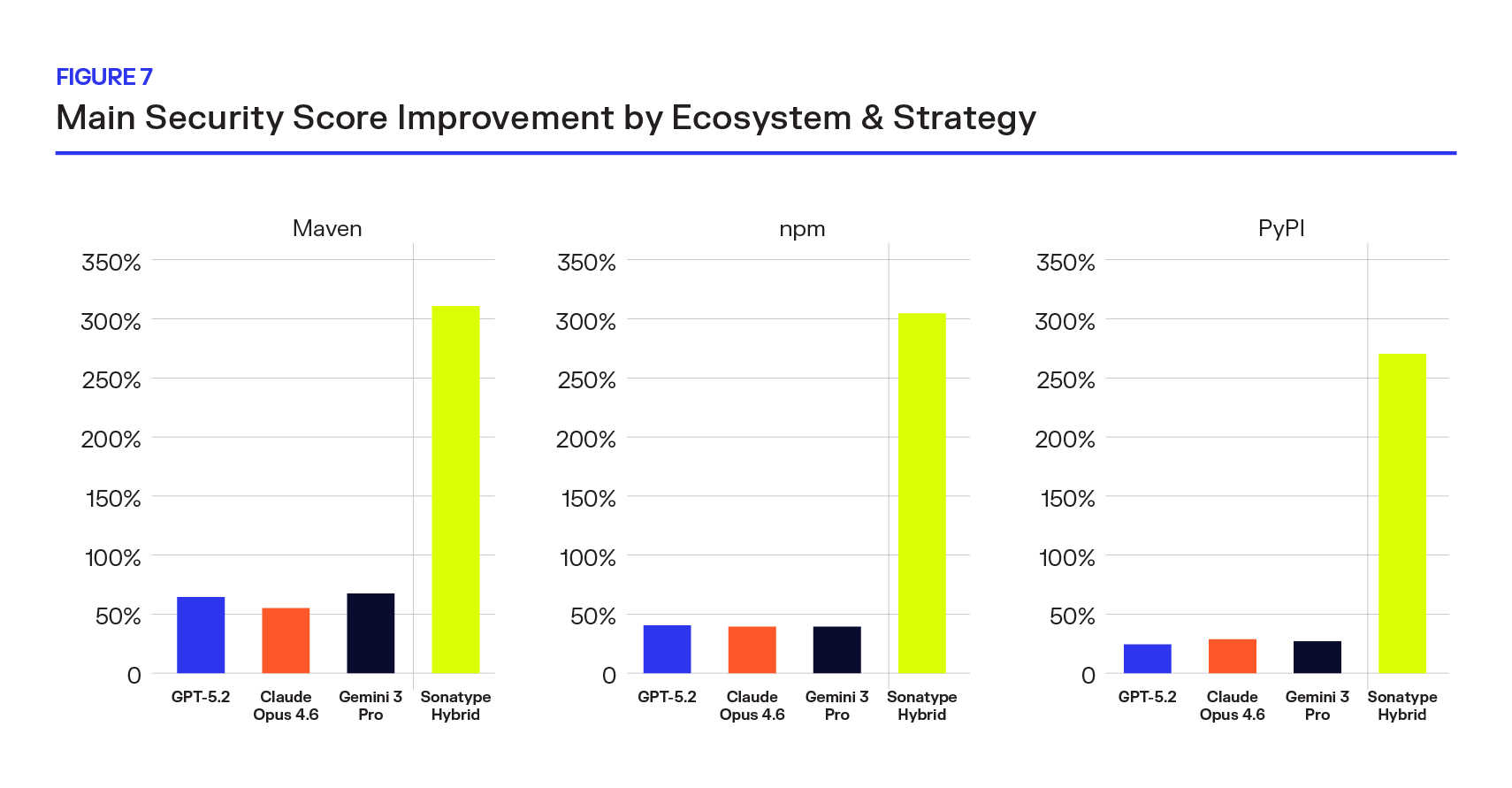

Full Recommendation Landscape
Up to this point, we have focused on “no-change” decisions and the cost of inaction. But what happens when we apply all of a model’s recommendations, including both upgrades and “stay put” choices?
Figure 9 shows the residual vulnerability counts by severity after implementing each model’s full set of recommendations across the ~37,000-component evaluation set.

The picture is sobering. Even the strongest-performing models leave behind 540+ Critical and 3,500+ High vulnerabilities. Across the newest generation — Gemini 3 Pro, GPT-5.2, and Claude Opus 4.6 — results cluster tightly.
The reduction over earlier models is real, but modest. No matter which frontier model is selected, roughly 4,100-4,200 Critical and High CVEs persist. That floor is stubbornly high.
The earliest model in the set, Claude Sonnet 3.7, leaves behind roughly 5,300 Critical and High vulnerabilities. The latest, Claude Opus 4.6, reduces that to roughly 4,100, an improvement of approximately 23% across nearly a year of rapid model releases. Meaningful progress, but far from transformative.
Medium-severity vulnerabilities follow the same pattern. They decline from roughly 4,700 in the earliest generation to about 3,700 in the newest, but plateau among the most recent models.
This clustering suggests we are approaching the ceiling of what ungrounded LLMs can achieve in dependency upgrade reasoning.
Even when models successfully avoid hallucinating and do recommend upgrades, they frequently select versions that still carry known vulnerabilities. The pattern is consistent with reasoning driven by recency heuristics, semantic versioning patterns, and naming signals, not by live security intelligence. Without access to current vulnerability data and structured upgrade strategies, the models cannot reliably identify the version that actually minimizes exposure.
All Models Benefit From Good Data
If the earlier charts isolated the cost of inaction, Figure 10 expands the lens to the entire recommendation landscape. The orange bars show the total Critical and High vulnerabilities remaining after applying each model’s full set of recommendations, upgrades and stay-put decisions combined, across the ~37,000-component evaluation set.

This is purely avoidable risk. When models are grounded in real-time open source intelligence, these vulnerabilities are not recommended, suggesting that the future of AI-assisted software development will be defined less by model scale and more by access to real-time intelligence.
Across models, when real-time intelligence is applied, the LLMs recommend between 6,400 and 9,900 fewer vulnerabilities rated Critical and High per run, with the remaining vulnerabilities representing No Path Forward. That translates to a 60-70% reduction in residual High-severity risk, regardless of which LLM you start from.
- Even the strongest-performing model in the set (GPT-5) sees 59% of its remaining risk eliminated.
- The weakest (Claude Sonnet 3.7) sees 69% removed.
- The newer generation — Gemini 3 Pro, GPT-5.2, Claude Opus 4.6 — all fall within the same reduction band.
What makes this chart interesting is the uniformity of avoidable risk. The retained vulnerabilities vary widely, from roughly 10,830 to 14,325 remaining Critical and High vulnerabilities, reflecting genuine differences in model recency, tuning, and upgrade behavior. But the benefit of grounding with the right intelligence is stable across every model.
The ceiling we observed earlier is not a hard limit on risk reduction. It is a limit imposed by operating without real-time vulnerability intelligence, registry validation, and upgrade strategies.
Once that intelligence layer is introduced, the residual risk floor collapses regardless of the underlying model.

A year of rapid model advancement, including roughly 4x hallucination reduction and substantial gains in reasoning capability, moved the needle from 6% to 10%. The newest models, Claude Opus 4.6, Gemini 3 Pro, GPT-5.2, cluster tightly between 9-10%.
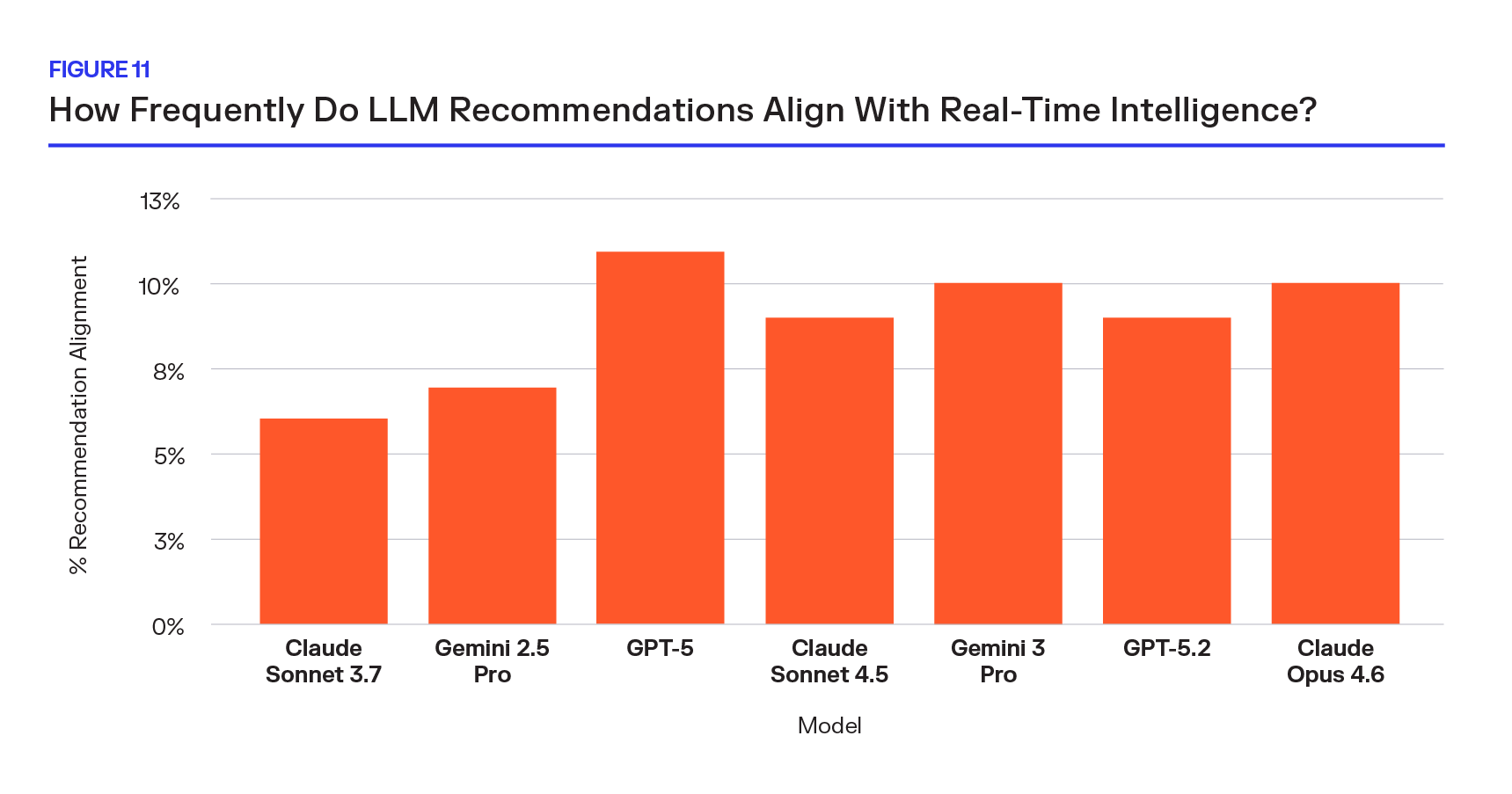
That is the full extent of convergence. What makes this result especially striking is its consistency across providers. OpenAI, Anthropic, and Google all land within the same narrow band. No model, regardless of size, generation, or release date, exceeds 11% agreement.
LLMs are not failing to reason syntactically about version numbers. They are reasoning without the inputs required to make the reasoning meaningful. And when these models have built-in reasoning, it is with commodity data — inherently lower quality. The version that minimizes security exposure, respects license constraints, and avoids breaking changes cannot be reliably inferred from static training data. It depends on live vulnerability disclosures, real registry state, and upgrade intelligence.
That information is not embedded in model weights.
Scaling parameters, refreshing training data, or tuning prompts does not materially close the gap. The divergence between probabilistic version selection and data-driven upgrade strategy is not shrinking with model improvement.
Without grounding in real-time supply chain data, LLMs will continue to recommend versions that differ from, and often perform worse than, strategies informed by live security analysis.
Mean Security Score Improvement Per Application
Revisiting a core metric from our prior study, Sonatype measured mean per-application security score improvement, and extends it with a larger dataset and a new generation of models. This analysis recreates the earlier methodology (originally presented in Figure 4), but with two important changes:
- An expanded sample size: an additional ~10,000 components were incorporated into the evaluation set.
- More conservative model behavior as shown in earlier sections, the newest foundation models default to “stay put” more frequently when uncertain.
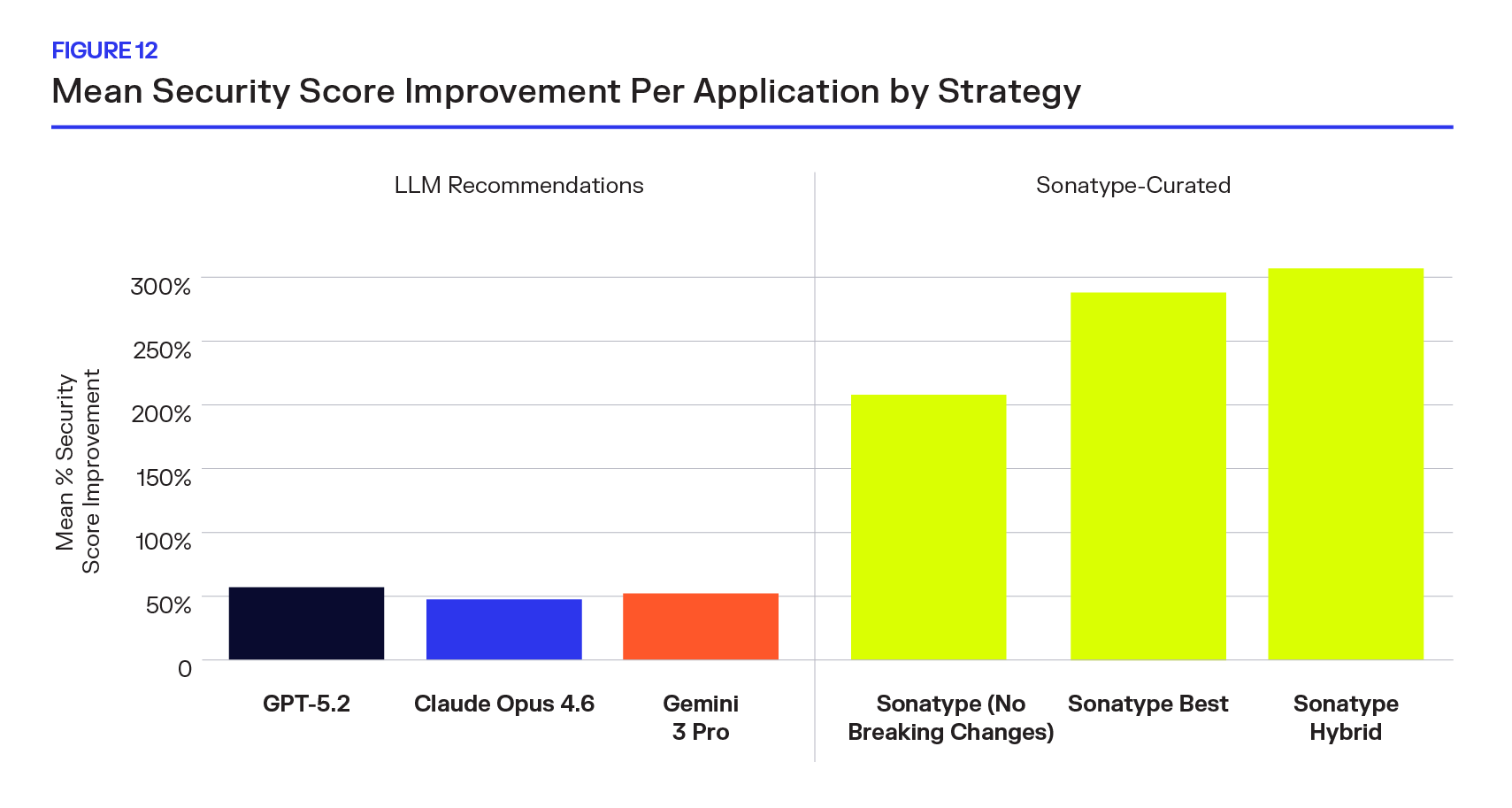
Across the updated sample, frontier LLM recommendations yield only modest average security improvements per application. By contrast, Sonatype’s curated strategies produce dramatically larger improvements. The magnitude gap is not incremental.
Even with a year of model advancements and substantial reductions in hallucination rates, the updated evaluation shows foundation models performing worse than what was previously reported for GPT-5 in the earlier study. The increased conservatism observed in newer models — more same-version recommendations, more abstention — directly reduces achievable security improvement.
Small Model + Sonatype Guide: The Grounding Experiment
The previous sections established that ungrounded LLMs face a structural ceiling: they hallucinate versions, default to inaction, and almost never choose the version a data-driven system would select. The gap is not closing with scale. But what if you flip the equation — give a small, cheap model access to the right data instead of throwing a larger model at the problem blind?
The Stress Test
To answer this, we built a subsample of ~400 components drawn from the full evaluation set, selecting the cases where models struggle most. Including known hallucinations, components with critical or high CVEs, and packages with less standardized versioning approaches.
The Setup
We equipped GPT-5 Nano, OpenAI's smallest and cheapest model, with a single tool: Sonatype Guide's version recommendation API. The model, 71x cheaper than Opus, can call the tool to look up ranked upgrade candidates with vulnerability data, license analysis, and breaking-change signals. It then reasons over the tool's response to make its final recommendation. No fine-tuning, no retrieval pipeline, just a cheap model with access to one good data source.
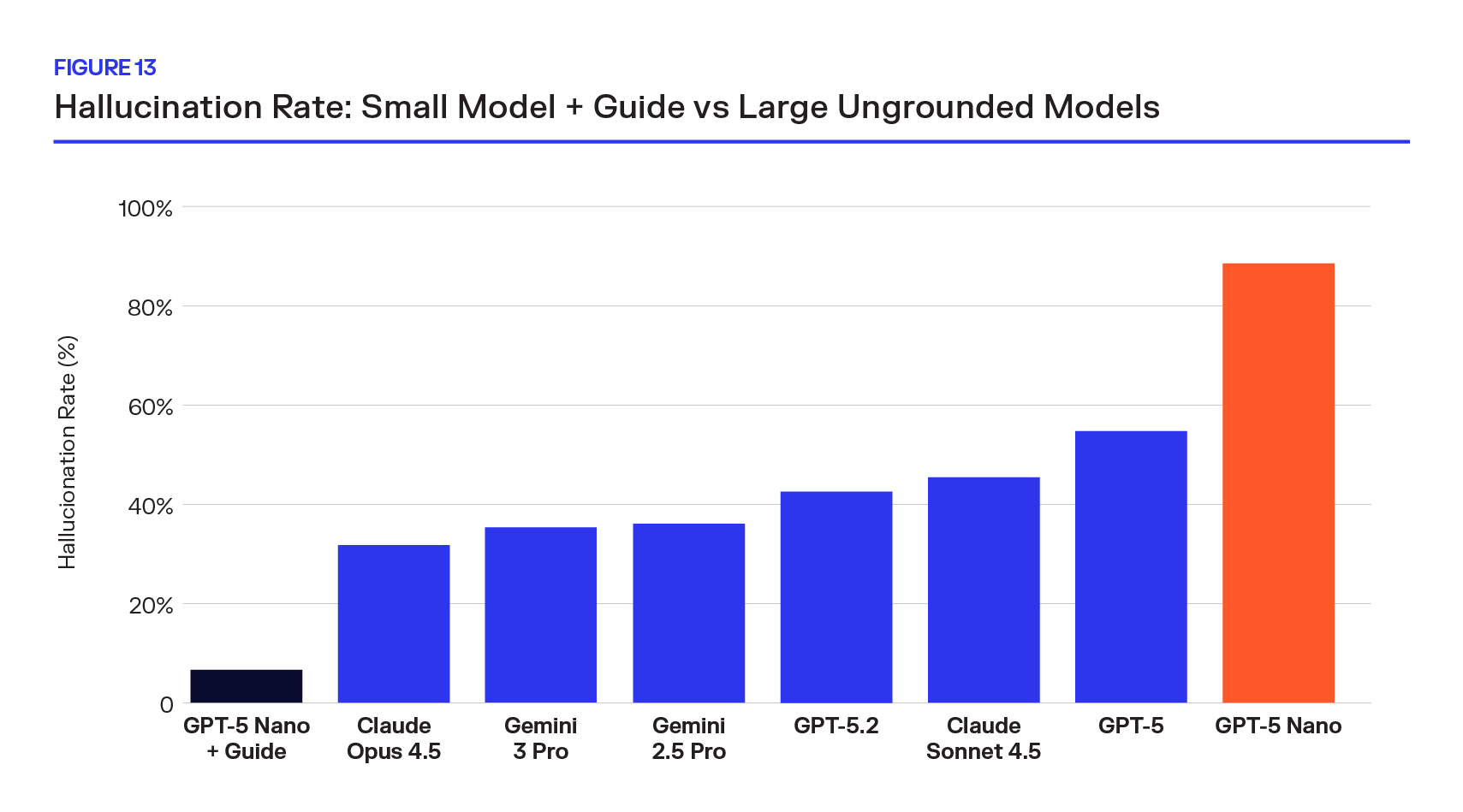
On the adversarial sample, GPT-5 Nano + Guide achieves a 6.8% hallucination rate, outperforming every ungrounded frontier model, including Claude Opus 4.6 (32.0%) and Gemini 3 Pro (35.8%).
The ungrounded Nano baseline sits at 88.9%, confirming that the dataset is genuinely difficult and that the improvement comes entirely from grounding. The cost differential sharpens the contrast: at $0.14 per million blended tokens, Nano’s inference costs are 32× lower than Gemini 3 Pro ($4.50/M) and 71× lower than Claude Opus 4.6 ($10.00/M), conservative comparisons given that frontier “thinking” models consume additional hidden reasoning tokens not reflected in per-token pricing. The implication is straightforward: on the components that matter most — vulnerable, ambiguous, and prone to hallucination, data access matters more than model scale.
The bottleneck was never capability, it was information. The security outcomes tell the same story. Many of these components have no clean upgrade path, every model, grounded or not, leaves behind residual vulnerabilities. But even here, the grounded model comes out ahead. Nano + Guide had 19 fewer Critical and 38 fewer High vulnerabilities than Opus 4.6, a model whose per-token inference cost is 71x higher. Grounding doesn't just prevent hallucinations; it steers the model toward versions with fewer known vulnerabilities when a perfect option doesn't exist.
The experiment confirms what the full-dataset analysis suggested: in generative AI software development, the gap between LLM recommendations and data-driven recommendations is not a model problem. It is a data problem.
Try Sonatype Guide for Free