Hands up, who has heard of Log4Shell? No? If you're a Java developer and this term isn't familiar to you then you might want to Google it right now. We'll wait.
The severity and impact of this vulnerability are so high that it's easy to miss that what makes this vulnerability deadly is not Log4J2, not JNDI, RMI, or LDAP, it's good old fashioned Java serialization. What those other technologies have done collectively is to make it trivially easy to exploit Java serialization weaknesses.
Fixing Log4J2 closes a door, but doesn't address the fundamental challenge.
Here's an analogy:
Imagine a bank created a chatbot. This chatbot was a great success, helping customers quickly resolve their queries. However, it was discovered that this chatbot would do whatever it was asked. Suddenly users exploited the chatbot to steal money from other accounts, clear their overdraft, etc. The bank quickly fixes the problem by removing the flexibility in the chatbot so it can now only do a few restricted things.
What's missed is the chatbot was the front end. In the background was a service that actually did the work. It's still there, happy to do whatever it's told. Shutting down the chatbot closes down one route, but doesn’t remove the underlying cause.
What This Series Is About
Log4Shell is a vulnerability that obviously had to be addressed, but it's only one route. There will always be others, while the Java serialization design remains flawed.
Many have asked why Java serialization continues to be available. This is a good question.
As we'll explain, serialization capability is a necessity for Java applications, and the native implementation is so highly performant and easy to use that it is widespread. Native Java serialization underpins the Java world. Disabling serialization is not an option. Improvements, reducing the chance of exploitation, even using different technologies. These are all options, and in this series of blog entries, we'll explore the choices and actions available.
Why Do We Need Java Serialization
Way back in time, before Java was even at version 1, it was recognized that the JVM had a peculiar 'achilles heel.'
Since Java is an object-oriented runtime, running a Java application can be seen as a complex graph of objects with associations to their relevant classes.
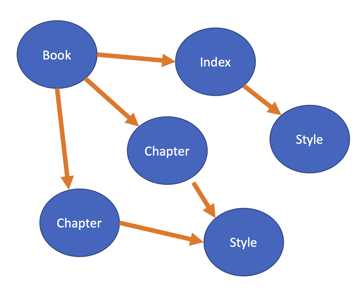
If that's unclear, consider this example. In this picture, there is a book object with references to its index page and its chapters. Each of these entities has their own type and unique data. In this example, each chapter shares the same style object, while the index has its own version. In the simplest of terms, that is an object graph, each blue circle represents some kind of object, the arrows represent the connection between the object. Serialization is the process, starting with an initial object, of following the references to all other reachable objects and converting them into a different form.
Real applications are much more complicated and typically consist of thousands, and sometimes millions or billions, of objects. Some of this graph is created as part of the application itself, but most will be deeply connected to any data that arrives from external sources. Load a record from a database, get a few hundred new objects added to the graph.
The number of objects that make up any application will always be significant, and it was quickly realized that there was no simple way to save the state of a JVM or share data from one JVM to another. Both of these are natural requirements. Quickly saving or restoring the state of a desktop or mobile application is an obvious need, and so is sharing data between two servers.
Java Serialization Design
The solution was to add a high-speed mechanism that could traverse a given object graph and convert it into a transmissible form (saving this form to disk is a trivial byproduct), another JVM could reconstitute that and/or later.
Many programming languages and runtimes have this type of capability, and the rules for traversing graphs to save or restore are well known. For object-oriented systems, there are a few particular considerations.
1: Object identity: Making sure that objects in the graph are the same instance where they need to be. Having duplicate versions of an object intended to be a singleton could be problematic! The solution was to include a special reference entry that allowed a previously saved or restored object to be referred to.
2: Scope of the object graph: Conceptually saving a single object could cause the complete contents of the Java heap to be serialized. Again, not an optimal outcome.
The design of Java serialization is to require classes to opt-in to the process by implementing the interface "java.io.Serializable." Relevant system classes have various strategies to avoid being opted-in from being declared a final class to hiding instances away so they can not be directly included in an application's object graph.
3: Polymorphism: Java's powerful object model means an instance of an object could potentially have many types. (A deeper guide to Java polymorphism is here). It's common for a field in an object to be of a type that is a Java interface, not a class. Similarly, with inheritance, the field type might be of a superclass while the actual object referenced is a subclass. For serialization purposes, the details of the actual, concrete, class of the instance must be recorded. Otherwise, how would the deserialization process know how to instantiate the right object when given just an interface or superclass name? As an example, imagine that a particular field is of type "Animal" and there are subclasses of type "Dog" and "Cat". How would the deserialization process pick the right type of "Animal" unless it has information that a "Dog" or a "Cat" was required? Java serialization records the actual class name during writing and uses the information to instantiate the correct concrete type during deserialization.
4: Instantiation: Given the name of a class to deserialize, there are two particular challenges. The first is structural. Classes may change form over time, and it is therefore important that there is an exact match in terms of the defined fields. The Java serialization design includes a particular version identifier generated either by the compiler or set by the developer. The identifier is included during serialization and checked during deserialization. Mismatches will terminate the deserialization process. The second element of instantiation is the process by which the instance is created. The aim, of course, is to create an instance of a class that is exactly how it was at the time it was serialized. The original object may have been mutated prior to its serialization. Some runtimes require that particular constructors are present to deal with this situation, but in Java serializations design constructors are not invoked. A literal empty instance of the class is created, and the fields are set directly from the deserialized data.
5: Internal data and portability: Not all data in an object is necessarily transportable. Some data is ephemeral or location-specific. For instance, serializing file or socket handles or recording when an object was created. There is also the consideration of portability. The serialization version ID mentioned previously could, if used precisely, require exactly the same class at both 'ends' of the serialization process. This certainly is not optimal, and sometimes a more flexible approach is required. The Java serialization process allows fields to opt-out by simply marking them 'transient.' Portability is significantly more complicated. The Java serialization design includes the option of having special methods declared on a class called during the appropriate stage. These methods must exist for every class in a class hierarchy, and must be designed to cope with all the different versions of the class that exist.
6: Performance: Java serialization is designed and coded to be fast. Using serialization as a form of persistence to disk is not a common operation. The primary use of serialization is the live transmission of objects to another system. So Java serialization is mostly used in data communications, and as such is expected to be as fast as possible. This need was apparent from the beginning and has always been a consideration when new features are added to the JVM or Java classes.
Next Time
We'll examine these particular characteristics and design points and reveal a few unexpected consequences. Read part two.

Try Nexus Repository Free Today
Sonatype Nexus Repository is the world’s most trusted artifact repository manager. Experience the difference and download Community Edition for free.